Modularisation du code (partie 1)
Require('explications');
Comme énoncé précédemment, il est judicieux de réutiliser le plus de code possible afin de limiter les copier-coller entre fichiers.
Si les pointeurs de fonctions nous permettent de réutiliser un socle de code commun, tout
écrire dans un seul fichier devient vite ingérable.
Perl ne contient pas vraiment de fonctionnalité de compilation séparé comme d'autres langages tels
que C, C# ou OCaml. Il est possible d'y créer des modules, mais cela nécessite notamment
de créer plusieurs fichiers qui suivent certaines conventions et de lire de la documentation,
ce qui me paraît overkill pour un petit projet comme celui-ci.
Il existe en revanche un mécanisme d'inclusion de fichier source dans un autre, au moyen de la primitive require. Le désagrément du fonctionnement de cette fonction est qu'elle évalue le contenu code du fichier passé en paramètre ; ainsi s'il y a du code dans l'espace de nom global (en dehors d'une sous-routine) il sera exécuté.
En outre, il faut que le code exécuté par require renvoie la valeur vraie. C'est pourquoi on trouve la mystérieuse ligne suivante à la fin de chaque fichier destiné à être inclus.
Première étape de modularisation
La première étape, dans la chronologie du développement, fût de séparer le code des procédures d'extractions de celui de la partie destiné à les exécuter. Ainsi la routine principale, nommé parcours-common.pl, contenait tout le code nécessaire au parcours des répertoires et à la génération des fichiers de sortie.
#/usr/bin/perl [...] # inclusion des modules nécessaires au programme @out_list = (); # variable globale qui contient les extraits sub main { my ($rep, $proc) = @_; [...] parcours_arborescence_fichiers($rep, $proc); [...] # écriture des résultats dans les fichiers de sortie [...] # fin de la fonction }
Le paramètre écrit en rouge est la référence vers une fonction d'extraction. La procédure main elle-même prend cette référence en paramètre.
# param $path : chemin du dossier dont les fichiers sont analysés # param $proc : référence vers la fonction d'extraction qui opère sur des fragments XML sub parcours_arborescence_fichiers { [...] # initialisation [...] # lecture du répertoire foreach my $file (@files) { next if $file =~ /^\.\.?$/; $file = $path."/".$file; if (-d $file) { parcours_arborescence_fichiers($file, $proc); } if (-f $file) { if($file =~ /\.xml$/i) { my $file_content = read_file($file); $file_content = decode("Detect", $file_content); my @titles = $proc->($file_content, "title"); push(@out_list, [clean(remove_outer_tag($titles[0])), "rubrique"]); foreach $item($proc->($file_content, "item")) { # en réalité on possède déjà tous les titres du fichiers dans @titles # mais on risque une désynchronisation si le nombre de balises titres # précédent le premier item n'est pas constant my @titre = $proc->($item, "title"); my @descr = $proc->($item, "description"); push(@out_list, [clean(remove_outer_tag($titre[0])), "titre"]); push(@out_list, [clean(remove_outer_tag($descr[0])), "description"]); } } } } }
On voit que la procédure passée en paramètre est appelée 4 fois.
Le code ainsi déclaré peut être utilisé dans d'autres fichiers. Ainsi, pour chaque implémentation de la fonction d'extraction, un fichier Perl existait. Dans celui-ci la procédure était définie, puis le script se contentait d'un appel à la fonction main définie dans la bibliothèque de code commun en lui passant en argument le répertoire de travail et la procédure précédemment définie.
On avait donc l'architecture suivante :
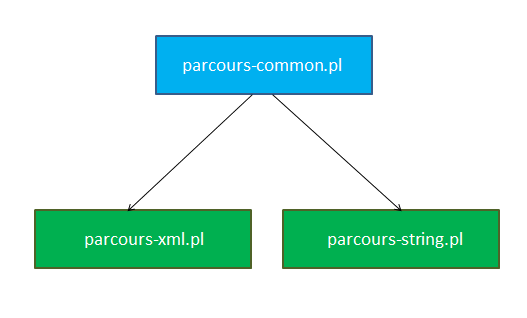
Le bloc bleu symbolise une bibliothèque de code, et les boîtes vertes représentent des scripts implémentant une fonction de callback et destinés à être exécutés.